Debezium
Working with database systems has always been a difficult and frustrating job. Recently, I had the opportunity to work with a new solution for databases used to detect changes from a database and Copy that data to another database of the same or different type. To solve this problem, I use a solution with a name like title - C hange D ata C apture or simply put, CDC.
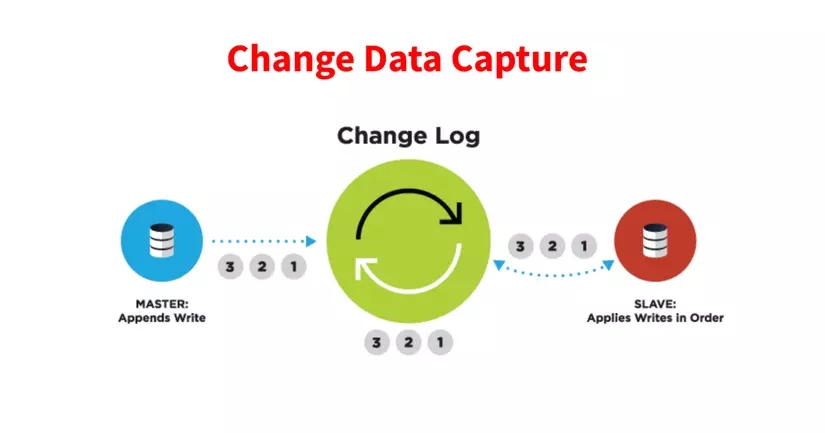
What is Change Data Capture?
As its name implies, catching data changes , this is the technique used for us to catch changes in data contained in the database. Catching changes in data will help us solve quite a few problems in data processing, which we will learn about in the next section.
To be able to catch this data change, there are many different ways, the most primitive we can use is the TRIGGER mechanism in already supported databases to catch ACTIONs about update, insert, delete, etc. .. Or more gently, we can use tools to do this, typically Debezium is the most prominent tool.
CDC Benefits
The first benefit that everyone can see is copying data to other systems . If talking about this benefit, some of you may say: Database systems already support replication mechanisms. Use it right away, why do you need to use an external tool that is a headache and is less stable? Okay, right! If you only need to copy data from databases of the same type (MySQL => MySQL, Mongo => Mongo), then using the database's features is best. However, now if you want to copy data from MySQL to MongoDB or from MySQL to PostgreSQL, there will be no such mechanism. In this problem CDC will stand in the middle to detect changes in the Database that needs to monitor and process data, then can use code to process and push data and the system needs to copy data.
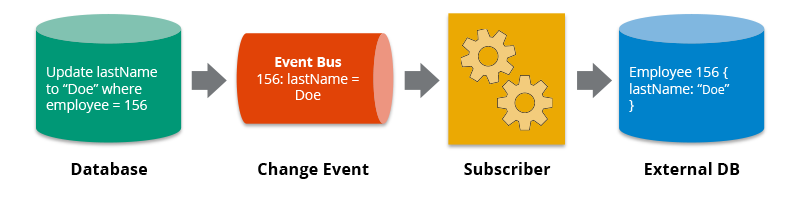
Another equally important benefit is the ability to back up data . Data change events will be stored, so if by chance your database drops at 9am, you can take a backup at 3am and reapply the saved changes from 3am to 9am. In theory, if you do not miss any events, your data will be fully restored as before it was dropped. Too much, right?
Continuing with the first benefit, after we copy data to another system we can use this system for testing instead of interacting directly on the real database system. It is not uncommon for developers to run queries that take minutes to process during testing, and even worse, can cause system locks. If this problem is mild, it will reduce system performance, if it is severe, it will cause a crash. CDC is also a way to help us minimize cases like this from happening.
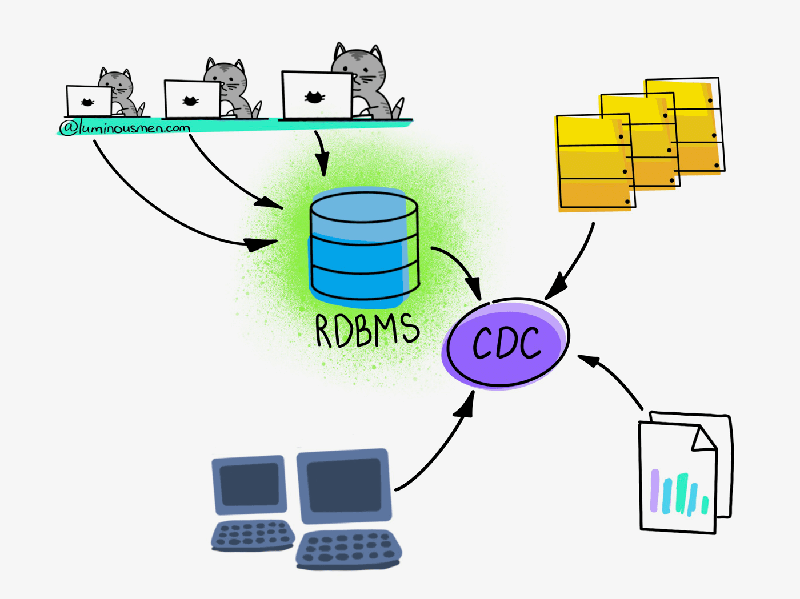
In addition, CDC also supports some specific problems of each system or processing Big Data. If you have ever applied CDC to these problems, please share with me below.
Debezium - CDC Tool
There's no use talking about theory without any examples, that's why I'll introduce a tool that I've had time to work with and find quite good, this tool is Debezium. Debezium at its core uses Kafka to generate messages corresponding to data change events. Debezium uses Connectors to connect to database systems and detect changes. Debezium 1.9 currently supports MySQL, PostgreSQL, MongoDB, Oracle, SQL Server, DB2, Cassandra, Vitess. You can see instructions for each connector at the official document: https://debezium.io/documentation/reference/2.0/connectors/index.html
This is Debezium's model, first of all we also have source DB - where we track data changes. Kafka Connect plays the role of detecting changes and pushing events into Apache Kafka. Data can then be pushed to sinks depending on usage needs.
In this section, I will describe the installation steps of MySQL, the type of database that everyone probably works with the most.
For MySQL, Debezium will rely on binlog to be able to detect changes in data, so for systems that need monitoring, you need to enable this binlog feature and make sure the user used to connect to needs to have it. permission to read binlog.
I work with Kubernetes a lot, so I will guide everyone to build this tool on K8s. For other environments like VM or Docker, there are basically similar components.
Debezium when running on K8s will use the Strimzi Operator (this is an Operator for Kafka). First we create a separate namespace for this application:
kubectl create ns debezium-example
Then we need to install Strimzi Operator
curl -sL https://github.com/operator-framework/operator-lifecycle-manager/releases/download/v0.20.0/install.sh | bash -s v0.20.0
Create Secret for demo database
Create User and assign permissions to Debezium
Now comes the important part, we will create a Kafka cluster to store changes events. The configuration below will create 1 kafka pod corresponding to 1 broker and 1 zookeeper pod.
Next we deploy a MySQL database to test, the user and password of this DB are mysqluser - msqlpw
Now we will deploy components that connect to MySQL and detect changes. First we need to create KafkaConnect to detect changes:
Then we deploy additional KafkaConnectors to connect to MySQL attached to the KafkaConnect created above
So the setup is complete and now we can monitor changes in the database. We run this command to listen for messages in kafka
Open another terminal. Now we will access the DB and add a record to test:
Add another record:
If you see a JSON message like the following, the setup was successful:
The message event notification will have 3 main items including source (source containing data, for example how much binlog file), before (data before change) and after (data after change). From the before and after sections, we will detect how the data has changed (edited, deleted or updated).
In addition, Debezium is also capable of doing many other tasks such as automatically replicating changes between 2 different DBs,...
Last updated