Automatic scaling Pods and clusters
In kubernetes, we scale horizontally by increasing the number of replicas properties of ReplicationController, ReplicaSet, Deployment. Vertical scale by increasing resource requests and Pod limits. We can do this manually, but there will be many disadvantages, we cannot sit all day to check when our application has the most clients using it so we can connect to the kubernetes cluster and type the command to scaleable, but we want this job to be automatic.
Kubernetes provides us with autoscaling based on detecting that the cpu or memory we specified has reached a scaling threshold. If we use the cloud, it can also automatically create additional worker nodes when it detects that there are no longer enough nodes for Pod deployment.
Horizontal pod autoscaling
Horizontal pod autoscaling is how we increase the replicas value in scalable resources (Deployment, ReplicaSet, ReplicationController, or StatefulSet) to scale the number of Pods. This job is performed by the Horizontal controller when we create a HorizontalPodAutoscaler (HPA) resource. The Horizontal controller will regularly check the Pod's metric, and calculate the appropriate number of pod replicas based on the current Pod's check metric with the metric value we specified in the HPA resource, then change the replicas field. of scalable resources (Deployment, ReplicaSet, ReplicationController, or StatefulSet) if necessary.
For example, the config file of an HPA would be as follows:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: micro-services-autoscale
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: microservice-user-products
minReplicas: 2
maxReplicas: 5
metrics:
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 70In the file above, we specify the scalable resource with the scaleTargetRef attribute, we select the resource we want to scale as Deployment and the name of that Deployment, we specify the number of min and max replicas with 2 attributes minReplicas, maxReplicas. The metric we want to collect is memory, with a threshold value of 70%. When the metric collected from the Pod exceeds this value, the autoscaling process will be executed.
Autoscaling process
The autoscaling process is divided into 3 stages as follows:
Collect metrics of all Pods managed by the scalable resource we specified in the HPA.
Calculate the required number of Pods based on collected metrics.
Update the replicas field of the scalable resource.
Collect metrics
Horizontal controller will not directly collect Pod metrics, but it will get it through another guy, called metrics server. On each worker node, there will be a guy called cAdvisor, this is a kubelet component, responsible for collecting metrics of Pods and nodes, then these metrics will be aggregated at the metrics server, and the horizontal controller. will retrieve metrics from metrics server.
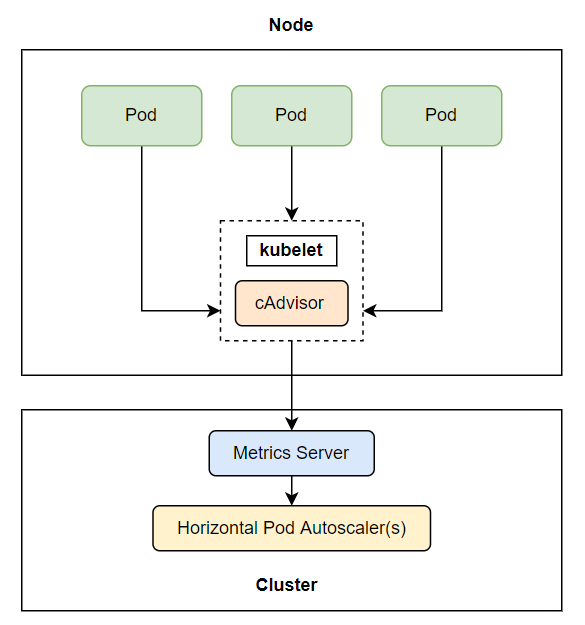
One thing we need to note here is that this metrics server is an add-on, but it is not available in our kubernetes cluster. If we want to use the autoscaling feature, we need to install this metrics server. You can see how to install it here https://github.com/kubernetes-sigs/metrics-server .
Calculate the number of Pods needed
After the horizontal controller collects the metric, it will proceed to the next stage which is to calculate the number of Pods based on the collected metric with the number of metrics we specify in the HPA, it will calculate the number of replicas from the two metrics above. according to an available formula. With the input value being a group of pod metrics and the output being the corresponding number of replicas. The simple formula is as follows:
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
Configuration has only one metric
When an HPA is configured with only one metric (only cpu or memory), calculating the number of Pods has only one step, using the above formula. For example, we have the current current metric value of 200m, desired value of 100m, current replicas of 2, we will have:
currentMetricValue / desiredMetricValue = 200m / 100m = 2
desiredReplicas = ceil[2 * (2)] = 4
Our number of replicas will now be scaled from 2 to 4. Another example is that we have the current current metric value of 50m, , the desired value is 100m, we will have:
currentMetricValue / desiredMetricValue = 50m / 100m = 0.5
The Horizontal controller will skip scaling up when the value is currentMetricValue / desiredMetricValueapproximately 1.
Configure multiple metrics
When our HPA is configured with many metrics, for example with both cpu and Queries-Per-Second (QPS), the calculation is not much more complicated, the horizontal controller will calculate the replicas value of each individual metric. odd, then the largest replicas value will be taken.
max([metric_one, metric_two, ...n])
For example, we have the number of replicas after calculating the CPU is 4, the Queries-Per-Second is 3, then max(4, 3) = 4, the number of replicas will be scaled to 4.

Update the replicas field
This is the final step of the autoscaling process, the horizontal controller will update the replicas value of the resoucre we specified in the HPA, and let that resoucre automatically increase the number of Pods or decrease the number of Pods. Currently, autoscaling only supports the following resources:
Deployments
ReplicaSets
ReplicationControllers
StatefulSets

Now we will practice to better understand this autoscaling process.
Scale according to CPU usage
Now we will create a deployment, and an HPA with the metric configuration being the number of CPUs used. Another thing to note is that when declaring a resource that we want to autoscaling, we must specify the resource request field for it, otherwise our resource will not be able to scale, because it does not have any threshold to calculate the desired metric.
Create a deployment.yaml file with the following configuration:
In the config file above, we create a Deployment with the number of replicas being 3, and cpu requests being 100m. Now we will create the HPA, create a file named hpa.yaml with the following configuration:
Create and test:
If you get hpa and see the target metric information is <unknown>/30%, then we will wait a bit for cAdvisor to collect the data.
When we get hpa again, if the target meritc field is 0%/30%then cAdvisor has reported data to the metrics server, and the horizontal controller has retrieved data from the metrics server. Have you noticed that in our REPLICAS school there is only 1 replica? When we created the deployment there were 3 replicas, why is there only 1 replica now? Let's get deployment and see.
We will also see that there is only 1 Pod in deployment, because now our Pod is not using any CPU, so HPA collects metrics and sees that the number of replicas needed is 0, so it scales down the number. The number of Pods is reduced to avoid wasting the node's resources, but because we have specified the minReplicas field as 1, our remaining number of Pods is 1 Pod.
Trigger scale up
We've seen that scale down works properly, now we'll see how scale up works. First we need to expose traffic so that the client can call the Pod created through Deployment above.
We run the following command to clearly see the scale up process of a resource.
Open another terminal.
After running the above command, go back to the terminal and run the watch command earlier, we will see that the number of cpu will increase, and accordingly, the number of Deployment replicas will also be scaled up.
When we describe hpa, we will see the scaling process plus how much the message scales up.
You will notice one thing here is that we have the target metric value of 294%, so according to the formula above, 294/30 = 9.8, ceil(9.8) must be equal to 10, why is the number of scale up only 4? replicas?
Maximun rate of scaling
Above, we should have scaled up to 10 replicas, but we only scaled up to 4 replicas because each time we scale, we have a limited number of replicas that can be scaled at once. Each time we scale, the maximum number of replicas we can scale is 2 times the current number of replicas, and if the current number of replicas is 1 or 2, the maximum number of replicas that will be scaled is 4 replicas.
For example, currently we have a number of Pods of 1. When scale up is triggered, the maximum number of Pods that can be scaled up is 4, and when the number of Pods is 4, then at the next scale up, the maximum number of Pods will be 4. You can scale it up to 8. Just double it.
And each time we scale up, we also have time between each other. For scale up, each time the scale is completed, it will trigger the next scale 3 minutes later, and for scale down, it will be 5 minutes. If you see that the number of target metrics has already exceeded the desired metric but why the scaling process has not been triggered, the answer is that it is not yet time for it to be triggered.
Scale theo memory
We see that scaling based on cpu usage is very easy. We can also configure it to scale based on memory usage. We just need to change the cpu value to memory when configuring, as follows:
But we need to note that when we choose to scale based on memory, we will encounter more problems than scaling based on cpu, because the release and use of memory will depend on the application inside the container. When we scale up the number of Pods based on memory, the system cannot be sure that the amount of memory used by each application will decrease, because this depends on how we write the application, if after we scale up Pod up, our application still uses as much memory as before, this scale up process will repeat over and over and reach the maximum Pod threshold of a worker node, and can cause the worker node to die. Therefore, when scaling a Pod based on memory, we need to consider more factors than just configuring HPA.
Scale according to other metrics
In addition to cpu and memory, kubernetes also supports a number of other metrics that we often need to use. Above we used the Resource type with cpu and memory, there are two other types: Pods and Objects.
Pod metric type includes any metrics related to the Pod. The two commonly used ones are QueriesPer-Second and number of messages in a message broker's queue (if we use a message broker). For example:
Object metrics are metrics that are not directly related to the Pod, but will be related to other resources of the cluster. For example ingress:
Above we specify the metric that will scale the number of replicas based on the request to the ingress controller.
Scaling down to zero replicas
Currently, HPA does not allow us to specify the minReplicas field to 0, even if our Pod does not use any resources, the number of Pods is still at least 1. Because scaling the number of replicas to 0 is not a good way. , because at the first request, we will not have any Pods to handle for the client, and this first initialization process is very time consuming.
Vertical pod autoscaling
We have seen that horizontal scaling helps us solve many application performance problems, but not all applications can be scaled horizontally, for example the AI model we mentioned above, which we need to scale horizontally. vertical style, increasing the Pod's resource usage.
We need to note that currently when I write this article, kubernetes does not have Vertical resource support available, but it is also an add-on, we need to install it to be able to use it. How to install VerticalPodAutoscaler here https://github.com/kubernetes/autoscaler/tree/master/vertical-pod-autoscaler .
An example of the VerticalPodAutoscaler configuration file is as follows:
With targetRef we will choose resoruce to collect metrics to scale, and updatePolicy.updateMode, we will have 3 modes: Off, Initial and Auto.
VPA component
VPA will have 3 components as follows:
Recommender: This component will monitor previously consumed resources and current resources to provide suggested cpu and memory request values.
Updater: This component will check whether the Pod managed by the scalable resource has the correct CPU and memory according to the value of Recommender provided above. If not, it will kill that Pod and recreate a new Pod with the correct CPU and memory requests. Correctly updated according to Recommender.
Admission Plugin: this is VPA's admission plugin added to the API server's available Admission Plugins, whose task is to change the Pod's resource requests when it is created to match the value of Recommender.
Update Policy
This policy will control how VPA applies changes to the Pod, specified through the updatePolicy.updateMode property . There are 3 values:
Off: In this mode, VPA only creates a recommendation, without applying that recommendation value to the Pod. We choose this mode when we only want to see the request value suggested to us, and we will decide whether to update it. Update CPU and memory requests to see if they match the suggested values.
Initial: in this mode, after recommendations are created, only new Pods created after this recommendation price will be applied will apply the suggested cpu and memory requests values, existing Pods remain the same. .
Auto: in this mode, after recommendations are created, not only Pods will have this suggested value applied, but also existing Pods whose values do not match the recommendations' value, it will be applied. will also be restarted.

Cluster autoscaler
We have found Horizontal Pod Autoscaling and Vertical Pod Autoscaling very useful, but what if we encounter the problem of scaling to the point where there are no more nodes for us to scale? Of course, at this point we can only scale by creating another worker node and letting it join the master node. When we run on the cloud, we can configure this process automatically. When our Pod is created and no node can contain it anymore, this Cluster Autoscaler will automatically create more nodes for us.
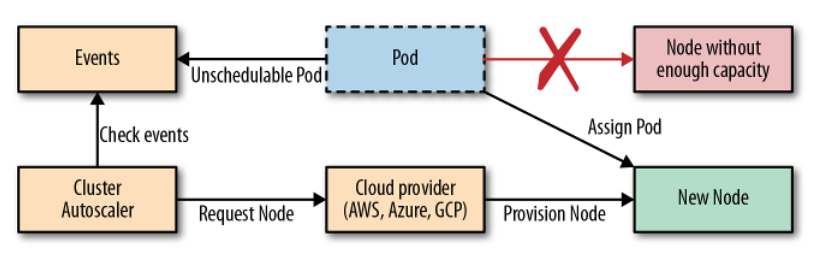
And then, our previously unscheduled Pod will be deployed to this new worker node. That's the process of scaling up, so what about scaling down? We can't let the worker node run all the time when we don't need the Pod to run on it, because using the cloud costs money. This scale down process will be a bit more complicated, Cluster Autoscaler will scale down a node when:
More than half of the capacity is not used, add up all the CPU and memory requests of the Pod, if less than 50% meets this requirement.
All existing Pods of that node, can be moved to another node without any problem.
There is nothing that can prevent that node from being deleted.
There are no remaining Pods that cannot be moved on that node.
If all of the above conditions are true, which defaults to about 10 minutes, the node will be removed from the kubernetes cluster. This deletion process consists of 2 steps, first the CA will mark the node as unschedulable and move the entire pod to another node, similar to the , command kubectl drain <node>, and then the node will be deleted.
CA is supported by:
Google Kubernetes Engine (GKE)
Google Compute Engine (GCE)
Amazon Web Services (AWS)
Microsoft Azure
With GKE we can enable autoscaling as follows:
For other platforms, you can see here https://github.com/kubernetes/autoscaler/tree/master/cluster-autoscaler .
Scaling Levels
We have talked about ways to scale an application up, here is an illustration of techniques that can be used to scale an application to different levels.
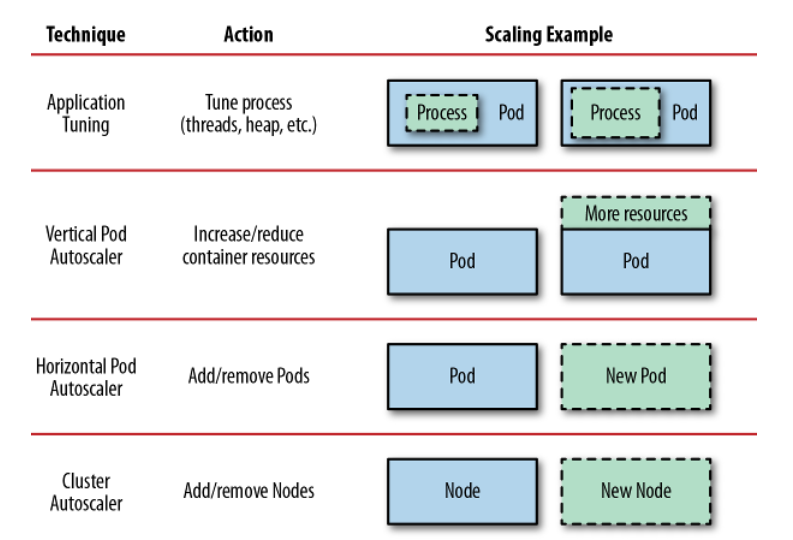
Application Tuning is not discussed in this article, because it depends on how the application is written. In this way, we will scale the process inside a container.
Horizontal Pod Autoscaling, as we said, will increase the number of Pods to perform a certain task, which will help the performance of our application become better.
Vertical Pod Autoscaling will increase the resource usage of the Pod, applicable to Pods that cannot be separated to run in parallel, such as AI models.
Cluster Autoscaling will increase the number of worker nodes, when we can no longer scale by Horizontal or Vertical.
Conclude
So we have finished learning about autoscaling inside the Kubernetes cluster. Using Horizontal Pod Autoscaling and Vertical Pod Autoscaling properly will help our application run extremely well for the client. If you have any questions or need further clarification, you can ask in the comment section below
Last updated