PersistentVolumes
PersistentVolumeClaims, PersistentVolumes
PersistentVolumes is a resource that will interact with the underlying storage architecture, and PersistentVolumeClaims will request storage from PersistentVolumes, similar to Pods. Pods consume node resources and PersistentVolumeClaims consume PersistentVolumes resources .
Normally when working with kubernetes we will have 2 roles:
kubernetes administrator: person who builds and manages kubernetes cluster, installs necessary plugins and addons for kubernetes cluster.
kubernetes developer: the person who will write the yaml config file to deploy the application on kubernetes.
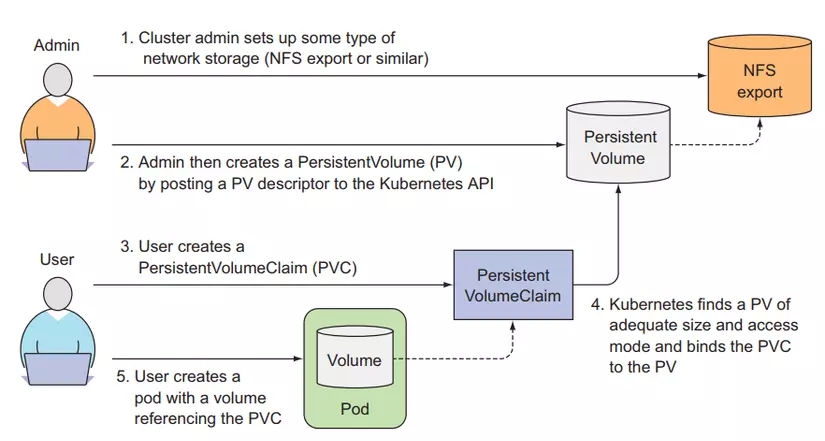
A kubernetes administrator will set up the storage architecture below and create PersistentVolumes for kubernetes developers to request and use.
Create PersistentVolumes
Now we will be a cluster administrator and we need to create a PersistentVolume so that cluster developers can request and use it. Create a file named pv-gcepd.yaml with the following configuration:
When the cluster administrator creates a PV, we need to specify the size of this PV, and we need to specify its access modes, which can be read and written by one node or multiple nodes. In the example above, only 1 node has the right to write to this PV, and many other nodes have the right to read from this PV. The storage architecture of this PV is gcePersistentDisk, we talked about this type of volume in the previous article. Let's try creating the PV we just wrote and list it out to see.
Now we have PV. Next, we will play the role of cluster developer to create PVCs and will consume this PV.
PersistentVolumes will not belong to any namespace. In kubernetes, there exist two types of resources: namespace resources and cluster resources. Like Pod, Deployment is a namespace resource. When creating a Pod, we can specify the namespace attribute and the Pod will belong to that namespace. If we do not specify a namespace, the Pod will belong to the default namespace. Cluster resources will not belong to any namespace, such as Node, PersistentVolumes resource.
Create PersistentVolumeClaim that consumes PersistentVolumes
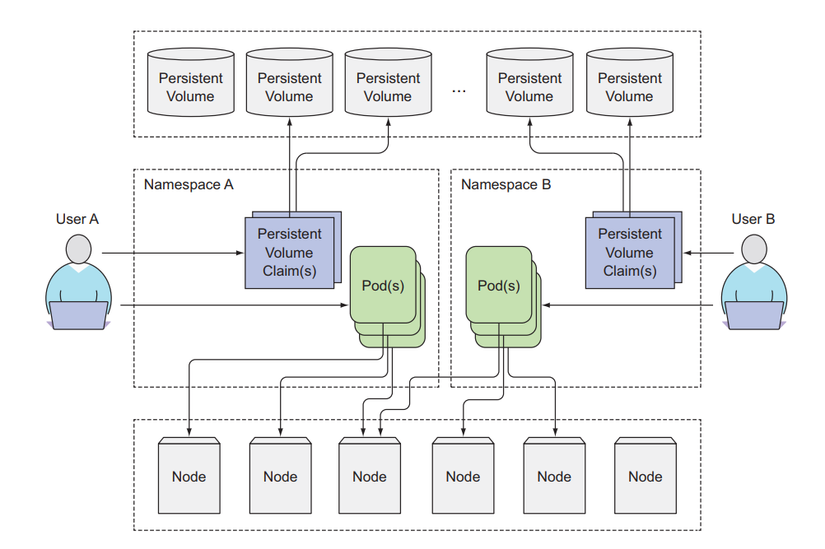
Now that we are developers, we need to deploy Pod and use a volume to store persistent data. Create a file named mongodb-pvc.yaml with the following configuration:
Here we will create a PVC named mongodb-pvc that requests 10Gi storage. If any PV meets it, then this PVCs will consume that PV's storage. And this PV only allows one worker node to read and write to it. Here there is an attribute storageClassName that we specify as empty, we will talk about this attribute below. Create PVCs and list them for viewing.
Our PVCs have been created and bound into PVCs. List the PVs we created above to see if it has been used by PVCs.
We see that the PV status has changed to Bound and the CLAIM column has shown that PVCs are consuming it.
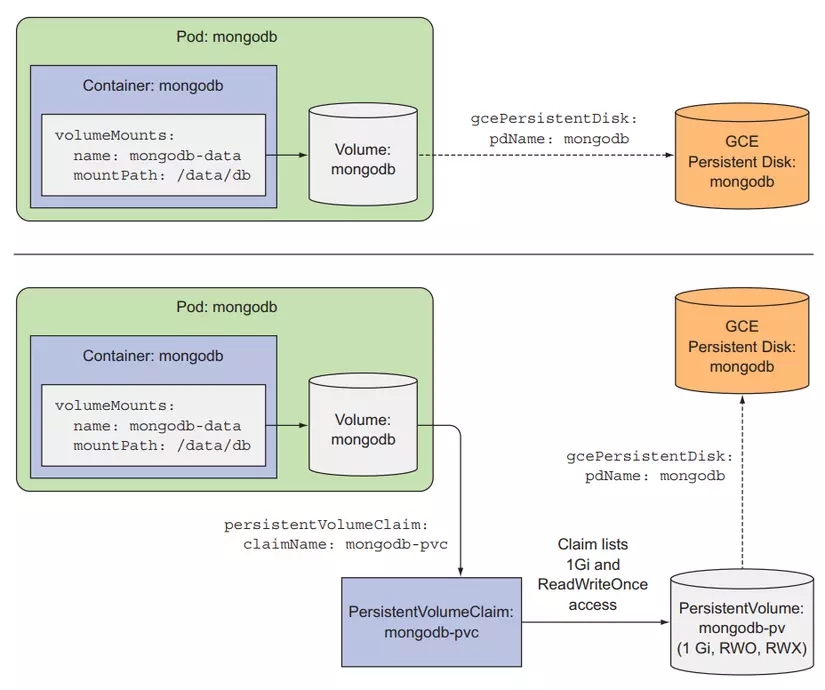
Create a Pod using PersistentVolumeClaim
Now we will create a Pod using PVCs, create a file named mongodb-pod-pvc.yaml with the following configuration:
To use PVCs, we specify it in the volume attribute of the Pod, so each PVCs can only be used by one Pod at a time. Now let's try to create a Pod and test, remember that in the previous lesson we created a gcePersistentDisk and inserted data into it.
kubectl create -f mongodb-pod-pvc.yaml
As we want, the data we created in the previous article is still here, in the Persistent Disk of google cloud.
Benefits of using PersistentVolumeClaim
In this article, you will see that compared to volume, using PersistentVolumeClaim requires more steps. But from a developer's perspective, when doing real work, now we just need to create PVCs and specify their size, then in the Pod we only need to specify the name of the PVCs, we do not need to work with the underlying storage architecture. our node, and we don't need to know whether our data is stored in the worker node or in the cloud storage or elsewhere. Those things are the cluster administrator's job.
And the config file of PVCs can be reused in other clusters. While we use volumes, we need to see what storage architectures the cluster supports first, so a config file may be difficult to use in other clusters. different.
Recycling PersistentVolumes
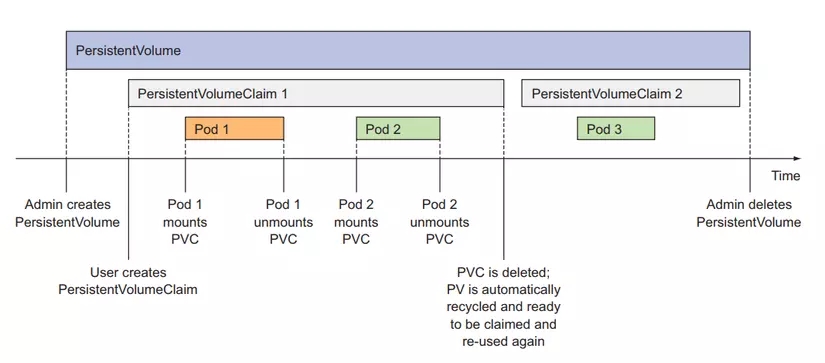
When creating a PV, we notice that there is an attribute called persistentVolumeReclaimPolicy. This attribute will define how the PV acts when PVCs are deleted. There are 3 modes:
Retain
Recycle
Delete
In Retain policy mode, when we delete PVCs, our PV still exists there, but the PV will be in the state of Release, not Available as originally, because it has already been used by PVCs and contains data. If you let the PVCs bound in, it can cause errors. Use this mode when you want to delete PVCs and your data will still be there. What you need to do is delete the PV manually, create a new PV, and create a new PV. Create new PVCs to re-bound.
Let's try deleting PVCs.
In Recycle policy mode, when we delete PVCs, our PV still exists there, but at this time the data in the PV will be deleted and the status will be Available so another PVC can consume it. Currently, GCE Persistent Disks does not support Recycle policy.
In Delete policy mode, when we delete PVCs, our PV is also deleted.
We can change the policy of an existing PV, such as switching from Delete to Retain to avoid data loss.
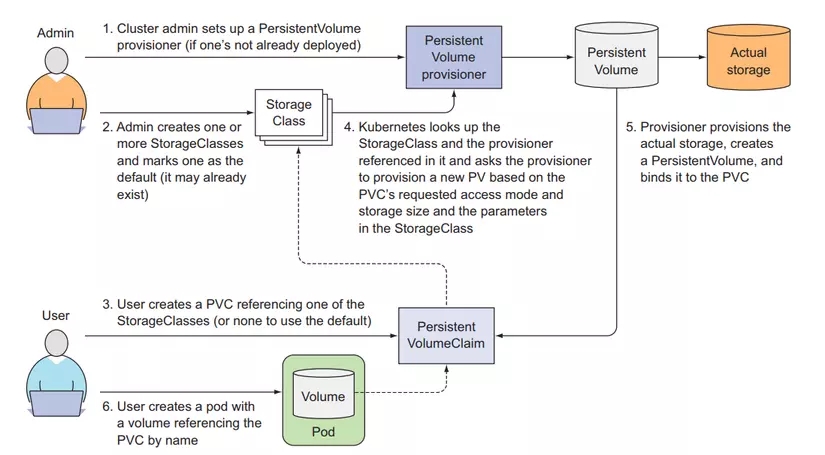
Automatic provisioning of PersistentVolumes (Dynamic provisioning)
We've seen how to use PV and PVCs together so that developers don't need to work with the underlying storage architecture. But we still need an administrator to set up those things first. To avoid that, Kubernetes provides a way to automatically create PV below.
The way the administrator sets up first is called Pre provisioning, while the automatic way is called Dynamic provisioning.
To do this, we will use StorageClasses with a provisioner (supported by the cloud by default), but for non-cloud environments, we must install a provisioner.
Create StorageClass
This is a resource that will automatically create PV for us. We only need to create StorageClass once, instead of having to configure and create a bunch of PV. Create a file named storageclass-fast-gcepd.yaml with the following configuration:
Here we create a StorageClass named fast, using gce-pd provisioner which will help us automatically create the PV below. When we create a PVCs, we specify storageClassName as fast. At this time, our PVCs will request to StorageClass, and StorageClass will automatically create a PV below for PVCs to use.
Create a file named mongodb-pvc-dp.yaml with the following configuration:
kubectl apply -f mongodb-pvc-dp.yaml
We will see a pvc-1e6bc048 automatically created by StorageClass.
Dynamic provisioning without specifying storage class
When we do not specify the storageClassName attribute in PVCs, it will use the default storage class. Let's list out the storage class. This is the storage class on google cloud, your local location may be different:
As in the config file above, we did not specify the storageClassName attribute, so these PVCs will default to using standard storageClassName.
Remember, in our original config file, we specified the storageClassName = "" attribute?
The meaning here is that we will not use storageClassName to automatically create PV, but we will use the existing PV. Why is that so? Why don't you just use the storage class to go faster instead of having to create a PV and then use it? That's a waste of time? As mentioned above, if you want to use the storage class, you need a provisioner. Currently, only the cloud supports provisioners. If you install on a regular data center , there is no provisioner available for you to use the dynamic function. Provisioning is okay.
Last updated