> For the complete documentation index, see [llms.txt](https://huy312100.gitbook.io/software-development/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://huy312100.gitbook.io/software-development/devops/kubernetes/volume.md).
# Volume
Volume is simply a mount point from the server's file system into the container.
Why do we need volumes? For containers, the things we write to its filesystem only exist while the container is running. When a Pod is deleted and recreated, a new container will be created, at this time everything we wrote in the previous container will be lost. If we want to retain that data, we must use volume.
In kubernetes, there will be the following volume types:
* emptyDir
* hostPath
* gitRepo
* nfs
* gcePersistentDisk, awsElasticBlockStore, azureDisk **(cloud storage)**
* cinder, cephfs, iscsi, flocker, glusterfs, quobyte, rbd, flexVolume, vsphereVolume, photonPersistentDisk, scaleIO
* configMap, secret, downwardAPI
* PersistentVolumeClaim
The above types of volumes are divided into 3 main types:
* Volume is used to share data between containers in Pod
* Volume attached to the filesystem of a node
* The volume is attached to the cluster and can be accessed by different nodes
We don't need to remember all the volume types, we can google it wherever we use it. We just need to remember some of the most commonly used types are **emptyDir, hostPath, cloud storage, PersistentVolumeClaim** . Secret, downwardAPI, configMap types we will talk about in the next articles.
When we run multiple containers in the same Pod, there will be times when we discover that we need different containers to be able to access the same folder to write data, and there will be other containers accessing the same folder. to get data for processing. How do we do that? Then kubernetes provides us with different types of volumes to do that. The first is emptyDir.
### Use emptyDir volume to share data between containers
emptyDir is the simplest type of volume, it will create an empty directory inside a Pod, containers in a Pod can write data inside it. Volume only exists for one lifecycle of the Pod. Data in this type of volume is only stored temporarily and will be lost when the Pod is deleted. We use this type of volume when we only want containers to be able to share data with each other and do not need to store data again. For example, log data is from a container running web API, and we have another container that will access that log to process the log.
We will make a simple example to make it easier to understand, create an emptydir.yaml file with the following configuration:
```yaml
apiVersion: v1
kind: Pod
metadata:
name: fortune
spec:
containers:
- name: html-generator
image: luksa/fortune
volumeMounts:
- name: html # The volume called html is mounted at /var/htdocs in the container
mountPath: /var/htdocs
- name: web-server
image: nginx:alpine
ports:
- containerPort: 80
protocol: TCP
volumeMounts:
- name: html # The volume called html is mounted at /usr/share/nginx/html in the container
mountPath: /usr/share/nginx/html
readOnly: true
volumes: # define volumes
- name: html # name of the volumes
emptyDir: {} # define type is emptyDir
```
The script's code in the **luksa/fortune** container .
```bash
#!/bin/bash
trap "exit" SIGINT
mkdir /var/htdocs
while :
do
echo $(date) Writing fortune to /var/htdocs/index.html
/usr/games/fortune > /var/htdocs/index.html
sleep 10
done
```
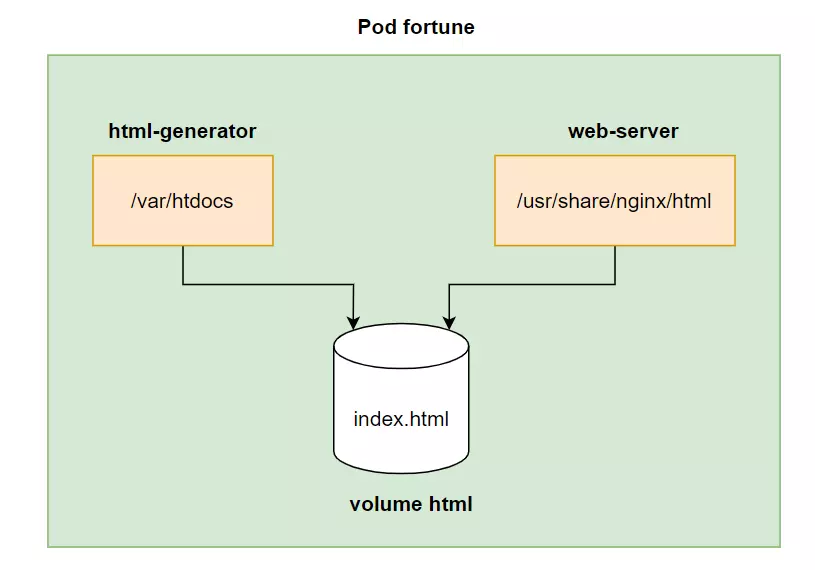
This html-generator container will generate any content every 10 seconds and save it to the index.html file. And we will have another container, named web-server, which will start a server and host content in the /usr/share/nginx/html folder (the default directory of nginx).
Here we have an emptyDir volume named html, mounted into the html-generator container in the /var/htdocs folder and the html-generator container will create an html index.html file in this emptyDir volume. And this emptyDir volume is mounted to the web-server container, in the /usr/share/nginx/html folder. So when we access the web container, we will see the content that the html-generator container has created.
Test to see if it works properly.
`kubectl apply -f emptydir.yaml`
```none
kubectl port-forward fortune 8080:80
Forwarding from 127.0.0.1:8080 -> 80
Forwarding from [::1]:8080 -> 80
```
`curl http://localhost:8080`
Note that emptyDir is only used to share data between containers, not to store persistent data. Next is a very useful volume type for static websites: gitRepo.
### Use gitRepo to clone git repository into container
**gitRepo is deprecated in version 1.25**
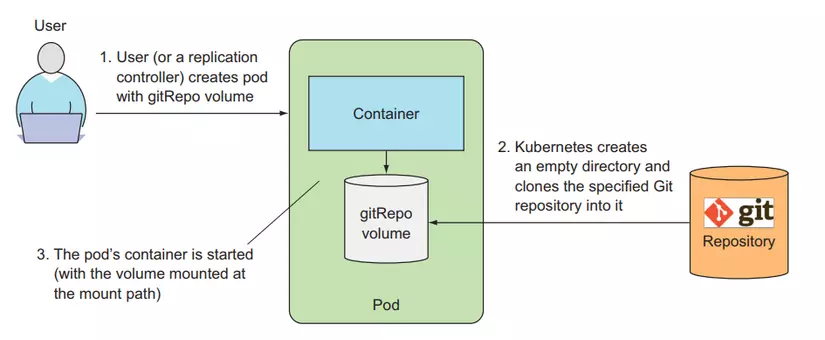
gitRepo is a volume type similar to emptyDir that will create an empty folder, and then it will clone the git repository code into this folder.
For example, create a file named gitrepo.yaml with the following configuration:
```yaml
apiVersion: v1
kind: Pod
metadata:
name: gitrepo-volume-pod
spec:
containers:
- image: nginx:alpine
name: web-server
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
readOnly: true
ports:
- containerPort: 80
protocol: TCP
volumes:
- name: html
gitRepo: # gitRepo volume
repository: https://github.com/luksa/kubia-website-example.git # The volume will clone this Git repository
revision: master # master branch
directory: . # cloned into the root dir of the volume.
```
In this example, the html volume is created with an empty folder, then the code in the kubia-website-example repository will be cloned to the root folder as we specified. (dot), this volume is mounted into the web-server container in the /usr/share/nginx/html folder. When we access Pod, we will see the static file content of kubia-website-example git repository.
For gitRepo volume, there is currently no private repository support. If you want to clone a private repository, you must use a pattern called **sidecar containers** . I will write a series about kubernetes pattern to talk about patterns in kubernetes, sidecar containers will be talked about later in that series.
The two types of volumes we just mentioned are only used to share data between containers, but in reality, we have a huge need to store persistent data, for example, a Pod runs a container database, we cannot let our Pod If we delete it, our stored data will be lost, so kubernetes provides us with types of volumes to store persistent data, first we will talk about the hostPath volume.
### Use hostPath to access the worker node's filesystem
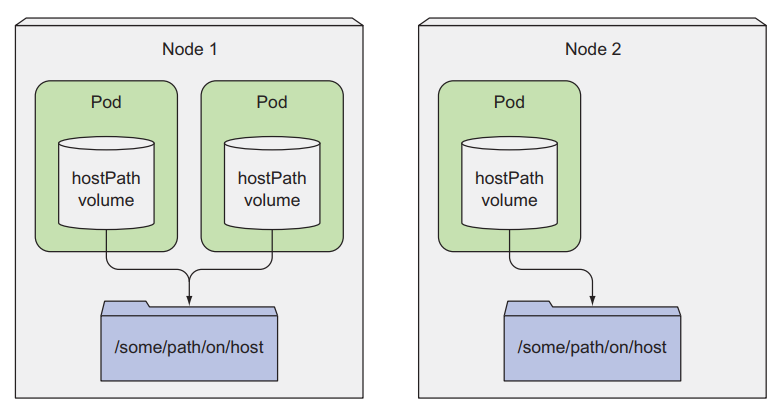
hostPath is the volume type that will create a mount point from the Pod to the node's filesystem. This is the first type of volume we'll talk about that can be used to store persistent data. Data stored in this volume only exists on one worker node and will not be deleted when the Pod is deleted.
For example:
```yaml
apiVersion: v1
kind: Pod
metadata:
name: hostpath-volume
spec:
containers:
- image: nginx:alpine
name: web-server
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
readOnly: true
- name: log # log volume
mountPath: /var/log/nginx # mounted at /var/log/nginx in the container
ports:
- containerPort: 80
protocol: TCP
volumes:
- name: html
gitRepo: # gitRepo volume
repository: https://github.com/luksa/kubia-website-example.git # The volume will clone this Git repository
revision: master # master branch
directory: . # cloned into the root dir of the volume.
- name: log
hostPath: # hostPath volume
path: /var/log # folder of woker node
```
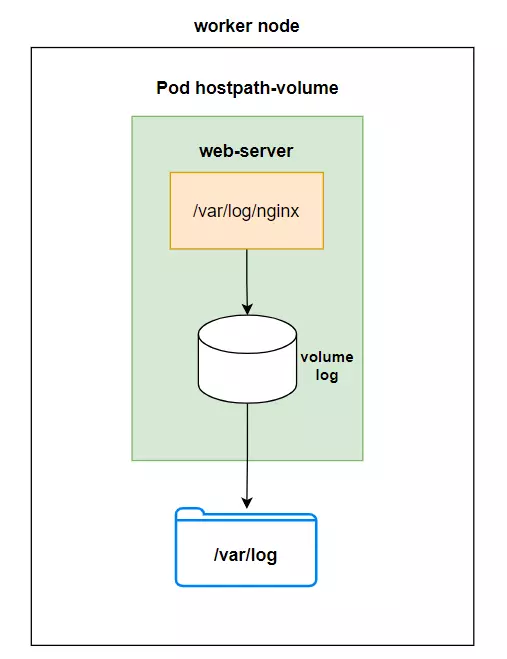
Here we will reuse the example above, and add a volume named log, which will be mounted to the worker node's file system in the /var/log folder, and this volume will be mounted to the web-server container in the / folder. var/log/nginx. At this point, all container logs will be stored in the /var/log folder of the worker node.
For this type of volume, our Pod needs to be created in the correct worker node for us to have the previous data. If our Pod is created in another worker node, then the Pod will not have the old data, because the old data is not available. Is it still located at the old worker node? We cannot use this type of volume for storing persistent data at all. What we want is that no matter which worker node the Pod is created on, our data will still be there, so it can be mounted into the container.
### Use cloud storage to store persistent data
This type of volume is only supported on cloud platforms, helping us store persistent data, even when Pods are created in different worker nodes, our data still exists for the container. The 3 most popular cloud platforms are AWS, Goolge Cloud, Azure corresponding to 3 types of volumes: gcePersistentDisk, awsElasticBlockStore, azureDisk.
So in this example we will use Google Cloud, if you have a Google Cloud account and have knowledge about it then you should follow, otherwise we will just see the example for more information. We use the following command to create a Persistent Disk on google cloud:
`gcloud compute disks create --size=1GiB --zone=europe-west1-b mongodb`
Create a file named gcepd.yaml with the following configuration:
```yaml
apiVersion: v1
kind: Pod
metadata:
name: mongodb
spec:
containers:
- image: mongo
name: mongodb
ports:
- containerPort: 27017
protocol: TCP
volumeMounts:
- name: mongodb-data
mountPath: /data/db
volumes:
- name: mongodb-data
gcePersistentDisk: # google cloud disk volume
pdName: mongodb # name of the persistent disk on google cloud
fsType: ext4
```
`kubectl create -f gcepd.yaml`
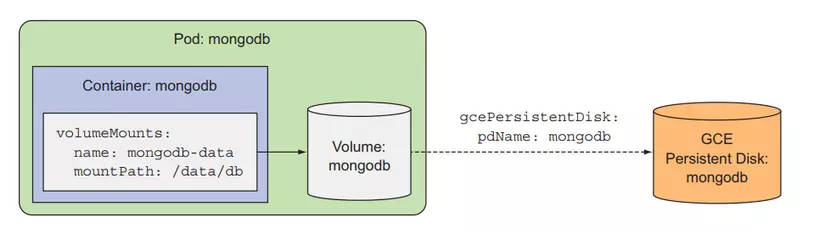
Here we will create a volume of type gcePersistentDisk with the name mongodb-data and mount it into the mongodb container in the /data/db folder.
Because of this type of volume, we will use GCE persistent disk, so it does not belong to any worker node but will reside on its own. When our Pod is created at any worker node, we can still mount it to this volume. And the data of this volume remains intact when the Pod deletes it.
To use another cloud storage volume, we just need to change the volume type, very simple, for example:
```yaml
apiVersion: v1
kind: Pod
metadata:
name: mongodb
spec:
...
volumes:
- name: mongodb-data
awsElasticBlockStore: # using AWS ElasticBlockStore instead of gcePersistentDisk
pdName: aws-ebs # name of the EBS on AWS
fsType: ext4
```
Now we will test it by writing data into the mongodb-data container, and we delete the Pod, when we create the Pod again, we will see that our data is still there.
```bash
$ kubectl exec -it mongodb mongo
MongoDB shell version: 3.2.8
connecting to: mongodb://127.0.0.1:27017
Welcome to the MongoDB shell.
...
```
```bash
> use mystore
switched to db mystore
> db.foo.insert({name:'foo'})
WriteResult({ "nInserted" : 1 })
> db.foo.find()
{ "_id" : ObjectId("57a61eb9de0cfd512374cc75"), "name" : "foo" }
```
`kubectl delete pod mongodb`
`kubectl create -f gcepd.yaml`
```bash
$ kubectl exec -it mongodb mongo
MongoDB shell version: 3.2.8
connecting to: mongodb://127.0.0.1:27017
Welcome to the MongoDB shell.
...
```
```bash
> use mystore
switched to db mystore
> db.foo.find()
{ "_id" : ObjectId("57a61eb9de0cfd512374cc75"), "name" : "foo" }
```
As we need, our data remains.
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://huy312100.gitbook.io/software-development/devops/kubernetes/volume.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.