gRPC
If you're aiming for high-performance, efficient APIs, gRPC is your go-to. It's designed for low-latency, high-throughput communication, often used in microservices architectures.
Why do we need gRPC?

Under the glory and brilliant development of REST API, basically the communication between client and server has been solved quite well. But in the age of Microservices, we clearly need a better way to increase load and throughput between services.
Maybe you won't find this a problem worth worrying about, especially when the system has few services and few servers/nodes. We are talking about a lot of services here and the load is very high. For example, a few hundred services and the load is somewhere above 100k CCU - Concurrent users (number of active users at the same time).
Then if a request needs to aggregate data across many services. At each service end, when receiving these intermediate requests, they must continuously encode and decode (eg: JSON data). This can overload the CPUs. The CPU should have been used for something more important than just en/coding intermediate data.
The idea of how to let services communicate with each other at the highest speed, reducing the encoding/decoding of data is the reason why gRPC was born.

RPC is not REST API
You can use common network programming techniques to send and receive RPC packets. However, developers always crave easier, more standardized methods. Since REST API was born and became popular, RPC has always used REST API to implement communication methods. This is called: RPC-based APIs.
The biggest difference is:
REST API: Client and Server need to exchange state through returned resources. Therefore, the returned response is usually a resource.
RPC: The client needs the server to perform calculations or return specific information. It's essentially the same as calling a function, it's just that the function is on a different server or another service. From there, the response returned is just the result of the "function", nothing more, nothing less.
Regarding mindset, if you want to get information about users with ID = 1. REST API returns full resource object user with ID = 1. But if you want to calculate total income of user = 1 this month, with RPC it returns Some total income is enough.
But the REST API usually returns a certain resource containing the user's total income information (for example, the user resource has the key "total_revenue").
If you still don't understand the difference, it's okay, it's not important. But remember that REST API methods only focus on creating, reading, editing and deleting resources. If so, you want the resource to do something or specifically calculate something, then it is RPC-base APIs.
What RPC-base APIs look like in practice:
POST /songs/:id/play (play song, if successful, return true or 1)
GET /songs/:id/calculate_total_views (returns the song's total views)

gRPC Advantages
gRPC provides a new take on the old RPC design method by offering many benefits in certain operations. Some of the gRPC strengths which have been increasing its adoption are as follows:
Performance
By different evaluations, gRPC offers up to 10x faster performance and API-security than REST+JSON communication as it uses Protobuf and HTTP/2. Protobuf serializes the messages on the server and client sides quickly, resulting in small and compact message payloads. HTTP/2 scales up the performance ranking via server push, multiplexing, and header compression. Server push enables HTTP/2 to push content from server to client before getting requested, while multiplexing eliminates head-of-line blocking. HTTP/2 uses a more advanced compression method to make the messages smaller, resulting in faster loading.
Streaming
gRPC supports client- or server-side streaming semantics, which are already incorporated in the service definition. This makes it much simpler to build streaming services or clients. A gRPC service supports different streaming combinations through HTTP/2:
Unary (no streaming)
Client-to-server streaming
Server-to-client streaming
Bi-directional streaming
Code Generation
The prime feature of gRPC methodology is the native code generation for client/server applications. gRPC frameworks use protoc compiler to generate code from the .proto file. Code generation is used in command of the Protobuf format for defining both message formats and service endpoints. It can produce server-side skeletons and client-side network stubs, which saves significant development time in applications with various services.
Interoperability
gRPC tools and libraries are designed to work with multiple platforms and programming languages, including Java, JavaScript, Ruby, Python, Go, Dart, Objective-C, C#, and more. Due to the Protobuf binary wire format and efficient code generation for virtually all platforms, programmers can develop performant applications while still using full cross-platform support.
Security
The use of HTTP/2 over the TLS end-to-end encryption connection in gRPC ensures API security. gRPC encourages the use of SSL/TLS to authenticate and encrypts data exchanged between the client and server.
Usability and Productivity
As gRPC is an all-in-one RPC solution, it works seamlessly across various languages and platforms. Additionally, it features excellent tooling, with much of the required boilerplate code generated automatically. This saves considerable time and enables developers to focus more on business logic.
Built-in Commodity Features
gRPC provides built-in support for commodity features, such as metadata exchange, encryption, authentication, deadline/timeouts and cancellations, interceptors, load balancing, service discovery, and so much more.
gRPC Disadvantages
As with every other technology, gRPC also has the following downsides that you need to be aware of when choosing it for developing applications.
Limited Browser Support
As gRPC heavily uses HTTP/2, it is impossible to call a gRPC service from a web browser directly. No modern browser provides the control needed over web requests to support a gRPC client. Therefore, a proxy layer and gRPC-web are required to perform conversions between HTTP/1.1 and HTTP/2.
Non-human Readable Format
Protobuf compresses gRPC messages into a non-human readable format. This compiler needs the message’s interface description in the file to deserialize correctly. So, developers need additional tools like the gRPC command-line tool to analyze Protobuf payloads on the wire, write manual requests, and perform debugging.
No Edge Caching
While HTTP supports mediators for edge caching, gRPC calls use the POST method, which is a threat to API-security. The responses can’t be cached through intermediaries. Moreover, the gRPC specification doesn’t make any provisions and even indicates the wish for cache semantics between server and client.
Steeper Learning Curve
Many teams find gRPC challenging to learn, get familiar with Protobuf, and look for tools to deal with HTTP/2 friction. It is a common reason why users prefer to rely on REST for as long as possible.
Working with Protocol Buffers
By default, gRPC uses Protocol Buffers, Google’s mature open source mechanism for serializing structured data (although it can be used with other data formats such as JSON). Here’s a quick intro to how it works. If you’re already familiar with protocol buffers, feel free to skip ahead to the next section.
The first step when working with protocol buffers is to define the structure for the data you want to serialize in a proto file: this is an ordinary text file with a .proto extension. Protocol buffer data is structured as messages, where each message is a small logical record of information containing a series of name-value pairs called fields. Here’s a simple example:
Then, once you’ve specified your data structures, you use the protocol buffer compiler protoc to generate data access classes in your preferred language(s) from your proto definition. These provide simple accessors for each field, like name() and set_name(), as well as methods to serialize/parse the whole structure to/from raw bytes. So, for instance, if your chosen language is C++, running the compiler on the example above will generate a class called Person. You can then use this class in your application to populate, serialize, and retrieve Person protocol buffer messages.
You define gRPC services in ordinary proto files, with RPC method parameters and return types specified as protocol buffer messages:
gRPC uses protoc with a special gRPC plugin to generate code from your proto file: you get generated gRPC client and server code, as well as the regular protocol buffer code for populating, serializing, and retrieving your message types. To learn more about protocol buffers, including how to install protoc with the gRPC plugin in your chosen language, see the protocol buffers documentation.
Core concept
Service definition
Like many RPC systems, gRPC is based around the idea of defining a service, specifying the methods that can be called remotely with their parameters and return types. By default, gRPC uses protocol buffers as the Interface Definition Language (IDL) for describing both the service interface and the structure of the payload messages. It is possible to use other alternatives if desired.
gRPC lets you define four kinds of service method:
Unary RPCs where the client sends a single request to the server and gets a single response back, just like a normal function call.
Server streaming RPCs where the client sends a request to the server and gets a stream to read a sequence of messages back. The client reads from the returned stream until there are no more messages. gRPC guarantees message ordering within an individual RPC call.
Client streaming RPCs where the client writes a sequence of messages and sends them to the server, again using a provided stream. Once the client has finished writing the messages, it waits for the server to read them and return its response. Again gRPC guarantees message ordering within an individual RPC call.
Bidirectional streaming RPCs where both sides send a sequence of messages using a read-write stream. The two streams operate independently, so clients and servers can read and write in whatever order they like: for example, the server could wait to receive all the client messages before writing its responses, or it could alternately read a message then write a message, or some other combination of reads and writes. The order of messages in each stream is preserved.
You’ll learn more about the different types of RPC in the RPC life cycle section below.
Using the API
Starting from a service definition in a .proto file, gRPC provides protocol buffer compiler plugins that generate client- and server-side code. gRPC users typically call these APIs on the client side and implement the corresponding API on the server side.
On the server side, the server implements the methods declared by the service and runs a gRPC server to handle client calls. The gRPC infrastructure decodes incoming requests, executes service methods, and encodes service responses.
On the client side, the client has a local object known as stub (for some languages, the preferred term is client) that implements the same methods as the service. The client can then just call those methods on the local object, and the methods wrap the parameters for the call in the appropriate protocol buffer message type, send the requests to the server, and return the server’s protocol buffer responses.
Synchronous vs. asynchronous
Synchronous RPC calls that block until a response arrives from the server are the closest approximation to the abstraction of a procedure call that RPC aspires to. On the other hand, networks are inherently asynchronous and in many scenarios it’s useful to be able to start RPCs without blocking the current thread.
The gRPC programming API in most languages comes in both synchronous and asynchronous flavors. You can find out more in each language’s tutorial and reference documentation (complete reference docs are coming soon).
RPC life cycle
In this section, you’ll take a closer look at what happens when a gRPC client calls a gRPC server method. For complete implementation details, see the language-specific pages.
Unary RPC
First consider the simplest type of RPC where the client sends a single request and gets back a single response.
The server can then either send back its own initial metadata (which must be sent before any response) straight away, or wait for the client’s request message. Which happens first, is application-specific.
Once the server has the client’s request message, it does whatever work is necessary to create and populate a response. The response is then returned (if successful) to the client together with status details (status code and optional status message) and optional trailing metadata.
If the response status is OK, then the client gets the response, which completes the call on the client side.
Server streaming RPC
A server-streaming RPC is similar to a unary RPC, except that the server returns a stream of messages in response to a client’s request. After sending all its messages, the server’s status details (status code and optional status message) and optional trailing metadata are sent to the client. This completes processing on the server side. The client completes once it has all the server’s messages.
Client streaming RPC
A client-streaming RPC is similar to a unary RPC, except that the client sends a stream of messages to the server instead of a single message. The server responds with a single message (along with its status details and optional trailing metadata), typically but not necessarily after it has received all the client’s messages.
Bidirectional streaming RPC
In a bidirectional streaming RPC, the call is initiated by the client invoking the method and the server receiving the client metadata, method name, and deadline. The server can choose to send back its initial metadata or wait for the client to start streaming messages.
Client- and server-side stream processing is application specific. Since the two streams are independent, the client and server can read and write messages in any order. For example, a server can wait until it has received all of a client’s messages before writing its messages, or the server and client can play “ping-pong” – the server gets a request, then sends back a response, then the client sends another request based on the response, and so on.
Deadlines/Timeouts
gRPC allows clients to specify how long they are willing to wait for an RPC to complete before the RPC is terminated with a DEADLINE_EXCEEDED error. On the server side, the server can query to see if a particular RPC has timed out, or how much time is left to complete the RPC.
Specifying a deadline or timeout is language specific: some language APIs work in terms of timeouts (durations of time), and some language APIs work in terms of a deadline (a fixed point in time) and may or may not have a default deadline.
RPC termination
In gRPC, both the client and server make independent and local determinations of the success of the call, and their conclusions may not match. This means that, for example, you could have an RPC that finishes successfully on the server side (“I have sent all my responses!”) but fails on the client side (“The responses arrived after my deadline!”). It’s also possible for a server to decide to complete before a client has sent all its requests.
Cancelling an RPC
Either the client or the server can cancel an RPC at any time. A cancellation terminates the RPC immediately so that no further work is done.
Warning
Changes made before a cancellation are not rolled back.
Metadata
Metadata is information about a particular RPC call (such as authentication details) in the form of a list of key-value pairs, where the keys are strings and the values are typically strings, but can be binary data.
Keys are case insensitive and consist of ASCII letters, digits, and special characters -, _, . and must not start with grpc- (which is reserved for gRPC itself). Binary-valued keys end in -bin while ASCII-valued keys do not.
User-defined metadata is not used by gRPC, which allows the client to provide information associated with the call to the server and vice versa.
Access to metadata is language dependent.
Channels
A gRPC channel provides a connection to a gRPC server on a specified host and port. It is used when creating a client stub. Clients can specify channel arguments to modify gRPC’s default behavior, such as switching message compression on or off. A channel has state, including connected and idle.
How gRPC deals with closing a channel is language dependent. Some languages also permit querying channel state.
How does gRPC work?
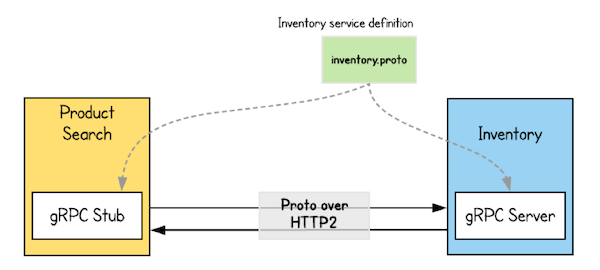
Returning to the story of increasing the load for the entire system of many services (or Microservices), Google has developed two things:
A new protocol to optimize connections, ensuring data is exchanged continuously with as little bandwidth as possible.
A new data format so that the two service ends (or client and server) can understand each other's messages with less encoding/decoding.
Google first developed an alternative protocol to HTTP/1.1 called SPDY. Later, this protocol was open source and even standardized, serving as the foundation for the HTTP/2 protocol. Once HTTP/2 was introduced, the SPDY protocol stopped being developed. gRPC officially operates on HTTP/2 after 2015.
HTTP/2 will work very well with binary instead of text. Therefore, Google invented a new binary data type called: Protobuf (full name is Protocol Buffers).
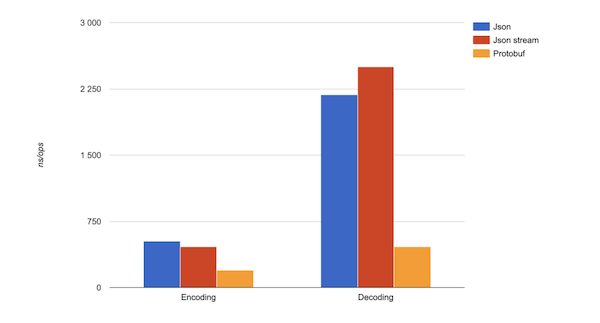
Some notes in gRPC
I have been using gRPC for about 2 years for medium and large systems. Below are points to note from personal experience:
gRPC should be used for backend to backend communication. The CPU does not bear much cost for encoding/decoding on each end anymore. However, the feature of each end requires importing the common model file (gene from the protobuf file), so if updated, it must be fully updated. This unintentionally creates dependencies for the users, many of you may not like this.
gRPC is often connected to a service mesh (or sidecar in Microservices), to be able to handle the HTTP/2 connection as well as monitor it better.
gRPC supports 2-way streaming, so it is very popular with fans of streaming systems and event sourcing (stream events). For example, gRPC is used in: vitess, neo4j for the above reason.
If gRPC is used for frontend-backend, it is really very considerate. Connection statefull creates a lot of discomfort in load scaling or you may get Head of line blocking (HOL).
gRPC still has Google's official gRPC Gateway library. That means you can still run 1 http/1 port for REST and 1 gRPC http/2 port at the same time. So it's not that there is no way to return to familiar REST, but of course going through a proxy service is more cumbersome.
Last updated