Query tuning
What is Query Tuning?
SQL can be said to be one of the indispensable skills for every programmer. Writing a query is actually quite simple. However, just writing the query is not enough; ensuring that the query is always executed effectively in practice is the difficult problem. That is why we must evaluate query performance and optimize the query ( Query Tuning ) if the query performance is low.
Query Tuning can be understood as rewriting a query so that it is executed faster, more efficiently, and is an inevitable thing to do if the current query has too low performance. So how to optimize the query, how to optimize? Let's find out together!
Query Processing và Query Execution
To learn how to optimize, we first need to understand how the process of processing and executing a query takes place.
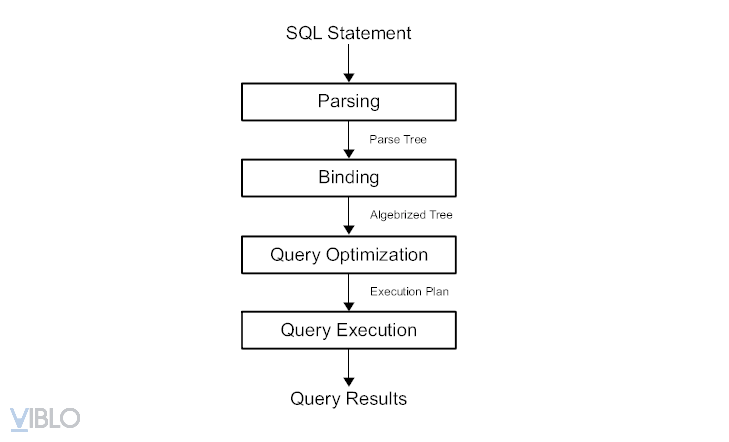
As you can see, the process includes:
Step 1 (Parse and binding): The query will be parsed into one
parse-treeand bound again into one.algebrized-treeInput: sql statement
Output: relational algebra expression.
For example:
For example:
Input
Output
𝑝𝑏𝑎𝑙𝑎𝑛𝑐It is<2500(Pi𝑏𝑎𝑙𝑎𝑛𝑐It is(𝑎𝑐𝑐𝑂in𝑛𝑡))pbalance<2500( Pibalance(account))
or
Pi𝑏𝑎𝑙𝑎𝑛𝑐It is(𝑝𝑏𝑎𝑙𝑎𝑛𝑐It is<2500(𝑎𝑐𝑐𝑂in𝑛𝑡))Pibalance( pbalance<2500(account))
Step 2: Optimization (Query Optimization)
Input: relational algebra expression
Output: query plan
In the following section, I will talk more about this step.
Step 3: Query Execution
Input: query plan
Output: query results
Query Optimization
The purpose of this step is to find the best execution plan for the query.
Note:
Input: relational algebra expression
Output: query plan
The optimizer lists all possible plans, gets information about the current state of the database, evaluates the cost of each plan, and then selects the best plan. . This process includes 3 steps:
1. Equivalent transformation
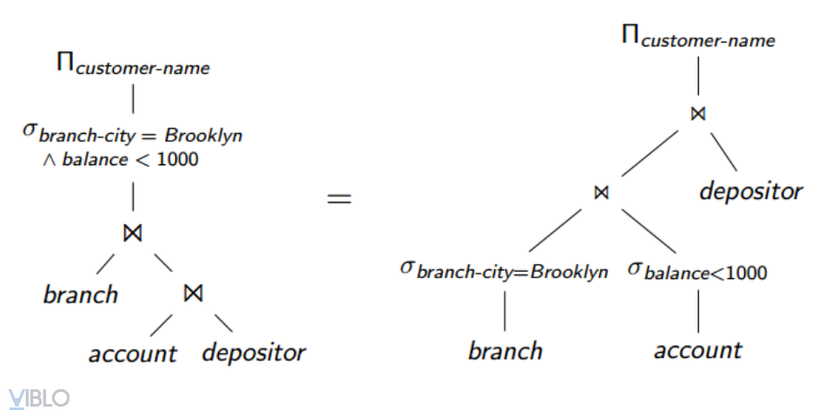
Two algebraic relational expressions are considered equivalence if they both produce the same result on the same legal data set (database that meets all integrity constraints specified in the strategy). database map)
The equivalence transformation rule is to transform a relational algebra expression into another equivalent relational algebra expression.
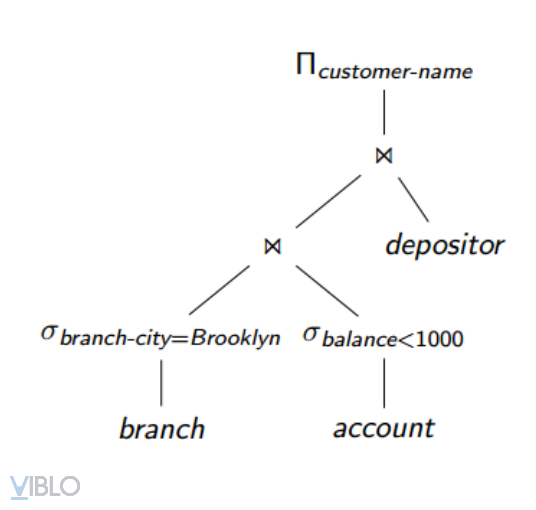
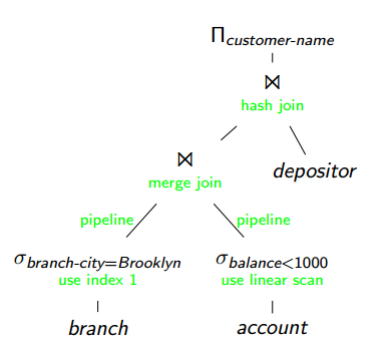
2. Create query plans
Algebraic expressions are not query plans
An algebraic expression can generate multiple query plans
In this step, we will add:
The indexes will be used, for joins or selects,...
Algorithms used: sort, merge or join,...
...
For example:
3. Estimate costs
The purpose of this step is to find the best query plan
These are costs
ƯỚC TÍNH, not actual costs
This cost is estimated based on factors such as:
Number of tuples per relation
Number of blocks on disk for each relation
Number of distinct values per field
histogram gives the value of each field
Based on the estimated cost, the "cheapest" query plan will be selected for the query optimization process.
Why Query Tuning?
After learning about Query Processing, do you think Query optimization is enough to optimize queries? The answer is not enough, because:
Transformations are only part of the query plan.
Only part of the plans are used.
Costs are estimates only.
If you perform Query Tuning to optimize the query right from the beginning of Query Processing, the Query Optimization process will be simplified and more effective. So we still need to do Query Tuning.
When is Query Tuning needed?
When queries run too slow
Queries accessing too much memory (retrieving from multiple tables)
Indexed queries are not used.
Some ways to Query Tuning
Get only the data you need:
Avoid SELECT *
Listing specific fields when using SELECT will help eliminate unnecessary fields from the query.
Name the result when SELECT to check the EXISTS condition
Avoid DISTINCT
DISTINCT will increase query time, so if you don't need it, it's best not to use it, especially for unique fields.
Limit the data you return by using TOP, LIMIT, or ROWNUM
Limit the use of nested queries
Using subqueries may not be effective if these subqueries are not correlated (attributes of the outer query are not used in subqueries).
As in the example in avoiding SELECT *, using INNER JOIN is more effective than using subquery:
Don't use HAVING when WHERE alone is enough
HAVING is often used with GROUP BY to conditionally limit the groups returned. However, if you use this clause in your query, the index will not be used, which can slow down the query.
The two queries above will return the same results on the same database but query_01will be faster because query_01they will set conditions to limit the returned results and query_02synthesize all results then use HAVING to remove the returned results. state other than "GA" and "TX".
Use clustering indexesto join
clustering indexesto joinquery_bwill be more effective query_bbecause:
Joining on two cluster indexes will allow merge join => better query efficiency.
Integer comparison is faster than string comparison
Note some system issues
LIKE and index
When using the LIKE operator, index will not be used if the pattern contains
%or_. Furthermore, this query can also retrieve a lot of unnecessary records.OR and index
Some systems never use index when using the OR operator. The reason is because indexes are used to quickly locate or look up data without having to search every row in the database.
can be replaced with
NOT and index
Similar to OR, index can also be used with the NOT operator instead
Let's write:
AND and index
Similar to OR and AND, it will slow down the query in some cases where it is used ineffectively such as:
you can change it to:
Order in the FROM clause: Ordering in FROM is not appropriate and will slow down your query unless the query has JOIN too many tables (8 tables or more).
Last updated